Qué es el archivo Robots.txt y cómo funciona
Piensa en un archivo robots.txt como si fuera un letrero de “Código de conducta” publicado en la pared de un gimnasio, un bar o un centro comunitario: el letrero en sí no tiene el poder de hacer cumplir las reglas enumeradas, pero los patrocinadores “buenos” seguirán las reglas, mientras que los “malos” probablemente las romperán y se harán bajar.
Un bot es un programa de computadora automatizado que interactúa con sitios web y aplicaciones. Hay bots buenos y bots malos, y un tipo de bot bueno se llama bot rastreador web. Estos bots “rastrean” las páginas web e indexan el contenido para que pueda aparecer en los resultados de los motores de búsqueda. Un archivo robots.txt ayuda a administrar las actividades de estos rastreadores web para que no sobrecarguen el servidor web que aloja el sitio web, o indexen páginas que no están destinadas a la vista pública.
Cómo funciona un archivo robots.txt
Los motores de búsqueda tienen dos trabajos principales:
- Crawling (rastrear) la web para descubrir contenido
- Indexar ese contenido para que pueda ser servido a los buscadores que buscan información.
Para rastrear los sitios, los motores de búsqueda siguen enlaces para llegar de un sitio a otro, rastreando miles de millones de enlaces y sitios web. Este comportamiento de rastreo a veces se conoce como “spidering”.
Después de llegar a un sitio web, pero antes de rastrearlo, el rastreador de búsqueda buscará un archivo robots.txt. Si encuentra uno, el rastreador leerá ese archivo primero antes de continuar a través de la página. Debido a que el archivo robots.txt contiene información sobre cómo el motor de búsqueda debe rastrear, la información encontrada allí instruirá la acción de rastreo adicional en este sitio en particular. Si el archivo robots.txt no contiene ninguna directiva que prohíba la actividad de un usuario-agente (o si el sitio no tiene un archivo robots.txt), procederá a rastrear otra información en el sitio.
Por qué es importante Robots.txt
Un archivo robots.txt ayuda a gestionar las actividades de los rastreadores web para que no sobrecarguen su sitio web o indexen páginas que no están destinadas a ser vistas por el público.
Aquí hay algunas razones por las que querría utilizar un archivo robots.txt:
1. Optimizar el presupuesto de rastreo
“El presupuesto de rastreo” es el número de páginas que Google rastreará en su sitio en cualquier momento. El número puede variar según el tamaño, la salud y los backlinks de su sitio.
El presupuesto de rastreo es importante porque si su número de páginas supera el presupuesto de rastreo de su sitio, tendrá páginas en su sitio que no están indexadas. Y las páginas que no se indexan no se clasificarán para nada.
Bloqueando páginas innecesarias con robots.txt, Googlebot (el rastreador web de Google) puede gastar más presupuesto de rastreo en páginas importantes.
2. Bloquear páginas duplicadas y no públicas
No necesita permitir que los motores de búsqueda rastreen todas las páginas de su sitio porque no todas necesitan clasificar. Los ejemplos incluyen sitios de preparación, páginas de resultados de búsqueda interna, páginas duplicadas o páginas de inicio de sesión.
WordPress, por ejemplo, automáticamente deshabilita /wp-admin/ para todos los rastreadores.
Estas páginas necesitan existir, pero no necesita que se indexen ni se encuentren en los motores de búsqueda. Un caso perfecto en el que usar robots.txt para bloquear estas páginas de los rastreadores y bots.
3. Ocultar recursos
A veces, querrá que Google excluya recursos como PDF, videos e imágenes de los resultados de búsqueda. Tal vez desee mantener esos recursos privados o hacer que Google se centre en contenido más importante. En ese caso, usar robots.txt es la mejor manera de evitar que se indexen.
Otros aspectos importantes que debes conocer sobre robots.txt
- Para que pueda ser encontrado, el archivo robots.txt debe estar ubicado en el directorio de nivel superior del sitio web.
- Robots.txt distingue entre mayúsculas y minúsculas: el archivo debe llamarse “robots.txt” (no Robots.txt, robots.TXT o de otra manera).
- Algunos agentes de usuario (robots) pueden optar por ignorar tu archivo robots.txt. Esto es especialmente común con rastreadores más nefastos como robots de malware o raspadores de direcciones de correo electrónico.
- El archivo /robots.txt es de acceso público: simplemente agrega /robots.txt al final de cualquier dominio raíz para ver las directivas de ese sitio web (¡si ese sitio tiene un archivo robots.txt!). Esto significa que cualquier persona puede ver qué páginas deseas o no que se rastreen, por lo que no debes usarlas para ocultar información de usuario privada.
- Cada subdominio en un dominio raíz usa archivos robots.txt separados. Esto significa que tanto blog.example.com como example.com deben tener sus propios archivos robots.txt (en blog.example.com/robots.txt y example.com/robots.txt).
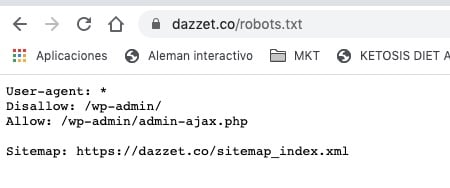
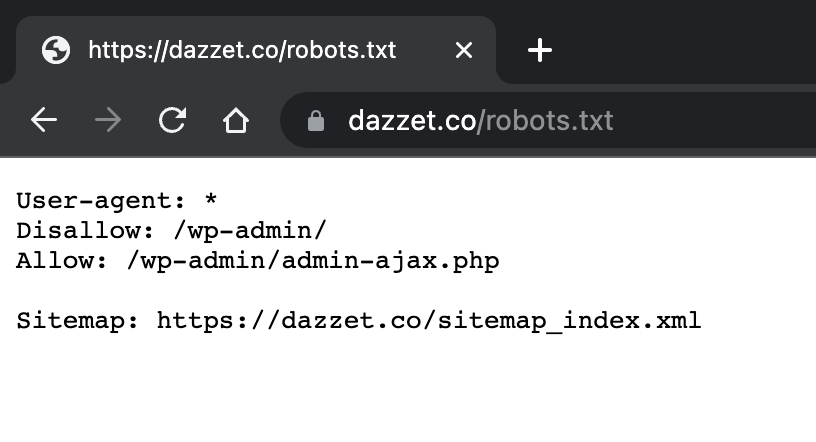
- En general, es una buena práctica indicar la ubicación de cualquier mapa de sitio asociado con este dominio al final del archivo robots.txt. Aquí tienes un ejemplo
Sintaxis técnica de robots.txt
La sintaxis de robots.txt puede considerarse como el “lenguaje” de los archivos robots.txt. Hay cinco términos comunes que probablemente encontrarás en un archivo robots. Incluyen:
- User-agent: El rastreador web específico al que le estás dando instrucciones de rastreo (generalmente un motor de búsqueda). Se puede encontrar una lista de la mayoría de los agentes de usuario aquí.
- Disallow: El comando utilizado para indicarle a un agente de usuario que no rastree una URL en particular. Solo se permite una línea “Disallow:” para cada URL.
- Allow (solo aplicable para Googlebot): El comando para indicarle a Googlebot que puede acceder a una página o subcarpeta aunque su página o subcarpeta principal esté prohibida.
- Crawl-delay: Cuántos segundos debe esperar un rastreador antes de cargar y rastrear el contenido de la página. Tenga en cuenta que Googlebot no reconoce este comando, pero la tasa de rastreo se puede configurar en Google Search Console.
- Sitemap: Se utiliza para indicar la ubicación de cualquier mapa del sitio XML asociado con esta URL. Tenga en cuenta que este comando solo es compatible con Google, Ask, Bing y Yahoo.
Dónde se coloca el archivo robots.txt en un sitio web
Cuando los motores de búsqueda y otros robots rastreadores web (como el robot de Facebook, Facebot) llegan a un sitio web, buscan un archivo robots.txt. Sin embargo, solo buscarán ese archivo en un lugar específico: el directorio principal (normalmente su dominio raíz o página de inicio). Si un agente de usuario visita www.ejemplo.com/robots.txt y no encuentra un archivo robots allí, asumirá que el sitio no tiene uno y procederá a rastrear todo en la página (y tal vez incluso en todo el sitio). Incluso si la página robots.txt existiera en, por ejemplo, ejemplo.com/index/robots.txt o www.ejemplo.com/pagina-de-inicio/robots.txt, no sería descubierta por los agentes de usuario y, por lo tanto, el sitio sería tratado como si no tuviera ningún archivo robots en absoluto.
Para asegurarse de que su archivo robots.txt sea encontrado, siempre inclúyalo en su directorio principal o dominio raíz.
Por qué necesitas un archivo robots.txt
Los archivos robots.txt controlan el acceso de los rastreadores a ciertas áreas de su sitio. Si bien esto puede ser muy peligroso si por accidente se prohíbe a Googlebot el acceso a todo el sitio (!!), hay algunas situaciones en las que un archivo robots.txt puede ser muy útil.
Algunos casos de uso comunes incluyen:
Evitar que se muestre contenido duplicado en las SERP (nota que meta robots suele ser una mejor opción para esto) Mantener secciones completas de un sitio web privadas (por ejemplo, el sitio de pruebas de su equipo de ingeniería) Evitar que las páginas de resultados de búsqueda internas aparezcan en una SERP pública Especificar la ubicación de un sitemap o varios sitemaps Evitar que los motores de búsqueda indexen ciertos archivos en su sitio web (imágenes, PDF, etc.) Especificar una pausa en el rastreo para evitar que sus servidores se sobrecarguen cuando los rastreadores cargan múltiples piezas de contenido a la vez Si no hay áreas en su sitio a las que desee controlar el acceso del agente de usuario, es posible que no necesite un archivo robots.txt en absoluto.
Prácticas recomendadas de SEO
- Asegúrate de que no estás bloqueando ningún contenido o sección de tu sitio web que desees que sea rastreado.
- Los enlaces en las páginas bloqueadas por robots.txt no serán seguidos. Esto significa que 1) a menos que también estén vinculados desde otras páginas accesibles por motores de búsqueda (es decir, páginas no bloqueadas a través de robots.txt, meta robots o de otra manera), los recursos vinculados no serán rastreados y es posible que no se indexen. 2) No se puede pasar ninguna equidad de enlace desde la página bloqueada al destino del enlace. Si tienes páginas a las que deseas pasar equidad, utiliza un mecanismo de bloqueo diferente al robots.txt.
- No uses robots.txt para evitar que los datos sensibles (como la información privada de los usuarios) aparezcan en los resultados de las SERP. Debido a que otras páginas pueden vincular directamente a la página que contiene información privada (burlando las directivas de robots.txt en tu dominio raíz o página de inicio), todavía puede ser indexada. Si deseas bloquear tu página de los resultados de búsqueda, utiliza un método diferente como la protección con contraseña o la directiva meta noindex.
- Algunos motores de búsqueda tienen múltiples agentes de usuario. Por ejemplo, Google utiliza Googlebot para la búsqueda orgánica y Googlebot-Image para la búsqueda de imágenes. La mayoría de los agentes de usuario de un mismo motor de búsqueda siguen las mismas reglas, por lo que no es necesario especificar directivas para cada uno de los rastreadores múltiples de un motor de búsqueda, pero tener la capacidad de hacerlo te permite ajustar con precisión cómo se rastrea el contenido de tu sitio.
- Un motor de búsqueda almacenará en caché el contenido de robots.txt, pero normalmente actualiza el contenido en caché al menos una vez al día. Si cambias el archivo y deseas actualizarlo más rápidamente de lo que está ocurriendo, puedes enviar la URL de tu robots.txt a Google.
miércoles, 22 de marzo de 2023
Juan Esteban Yepes
